VarietySound: Timbre-Controllable Video to Sound Generation via Unsupervised Information Disentanglement
This is an Demopage and Appendix of the paper submmited to ICASSP2023 ‘VarietySound: Timbre-Controllable Video to Sound Generation via Unsupervised Information Disentanglement’, which gives the demo video of proposed model and supplies some content not included in the paper (e.g. Detailed explanation of experimental results and so on).
Index
Abstract
Video to sound generation aims to generate realistic and natural sound given a video input. However, previous video-to-sound generation methods can only generate a random or average timbre without any controls or specializations of the generated sound timbre, leading to the problem that people cannot obtain the desired timbre under these methods sometimes. In this paper, we pose the task of generating sound with a specific timbre given a video input and a reference audio sample. To solve this task, we disentangle each target sound audio into three components: temporal information, acoustic information, and background information. We first use three encoders to encode these components respectively:
- 1) a temporal encoder to encode temporal information, which is fed with video frames since the input video shares the same temporal information as the original audio;
- 2) an acoustic encoder to encode timbre information, which takes the original audio as input and discards its temporal information by a temporal-corrupting operation;
- 3) and a background encoder to encode the residual or background sound, which uses the background part of the original audio as input.
Then we use a decoder to reconstruct the audio given these disentangled representations encoded by three encoders. To make the generated result achieve better quality and temporal alignment, we also adopt a mel discriminator and a temporal discriminator for the adversarial training. In inference, we feed the video, the reference audio and the silent audio into temporal, acoustic and background encoders and then generate the audio which is synchronized with the events in the video and has the same acoustic characteristics as the reference audio with no background noise. Our experimental results on the VAS dataset demonstrate that our method can generate high-quality audio samples with good synchronization with events in video and high timbre similarity with the reference audio.
Task Introduce
The current video-to-sound generation works share a common problem: all of their acoustic information comes from the model’s prediction and cannot control the timbre of the generated audio. To match this problem, we defined a task called Timbre Controllable Video to Sound Generation (TCVSG), whose target is to allow users to generate realistic sound effects with their desired timbre for silent videos.
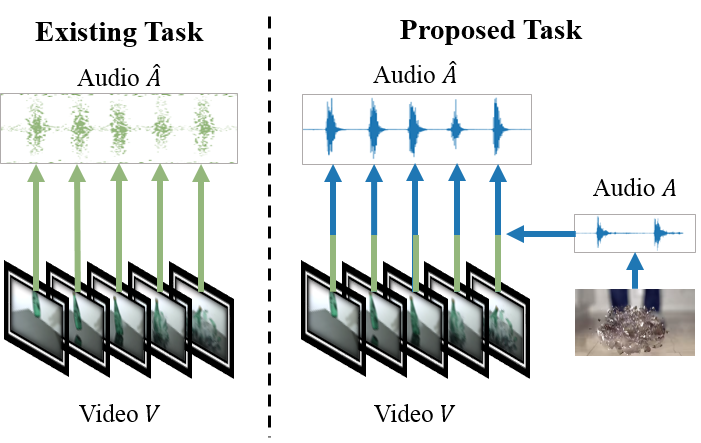
we have a video clip V of an object breaking for movie production, but the natural recorded sounds are not impressive enough. So with this task, we can use an additional audio A with a more remarkable sound of breaking to generate an audio track for V . The generated audio Aˆ will be time-aligned with V , but has the same kind of sound as A which will make the video more exciting. As far as we know, we are the first to propose this task.
Demo Videos
| Category | Original Video | Reference Audio | Baseline | Proposed |
|---|---|---|---|---|
| Baby | ||||
| Cough | ||||
| Dog | ||||
| Drum | ||||
| Fireworks | ||||
| Gun | ||||
| Hammer | ||||
| Sneeze |
Method Detail
Our method is a process of information disentanglement and re-fusion. We first disentangle the final audio information into three components: temporal information, timbre information, and background information, modeling them with three different encoders respectively, and then use a mel decoder to recombine these disentangled information for the reconstruction of the audio. The disruption operations and the bottlenecks force the encoders to pass only the information that other encoders cannot supply, hence achieving the disentanglement; and with the sufficient information inputs, the mel decoder could finish the reconstruction of the target mel-spectrogram, hence achieving the re-fusion. We also adopt the adversarial training, which helps the model to fit the distribution of the target mel-spectrogram better and thus obtain higher quality and better temporal alignment generation results.
Information Components Describe
Temporal Information
The temporal information refers to the location information in the time sequence corresponding to the occurrence of the sound event. In the temporal sequence, the position where the sound event occurs strongly correlates with the visual information adjacent to that position for real recorded video. Therefore, in our method, this part of the information will be predicted using the visual feature sequence of the input video. We also set a suitable bottleneck to ensure that the video can provide only temporal information without providing other acoustic content information.
Timbre Information
Timbre information is considered an acoustic characteristic inherent to the sound-producing object. The distribution of timbres between different categories of objects can vary widely, and the timbres of different individuals of the same category of objects usually possess specific differences. In our method, this part of the information will be predicted by the reference audio. The random resampling transform refers to the operations of segmenting, expand-shrink transforming and random swapping of the tensor in the time sequence. When encoding the reference timbre information, we perform a random resampling transform on the input reference audio in the time sequence to disrupt its temporal information.
Background Information
Background information is perceived as timbre-independent other acoustic information, such as background noise or off-screen background sound. This part of the information is necessary for training to avoid model confusion due to the information mismatch. We found that the energy of this part of the information is usually much smaller in the mel-spectrogram than the part where the timbre information is present. Therefore, in the proposed method, we adopt an Energy Masking operation that masks the mel-spectrogram of the part of the energy larger than the median energy of the whole mel-spectrogram along the time dimension. The energy masking operation discards both temporal and timbre-related information of the mel-spectrogram, preserving only the background information in the audio. In the training phase, this information is added to match the target mel-spectrogram; in the inference phase, this information will be set to empty to generate clearer audio.
Training and Inference
In the training phase of the generator, we use video features and mel-spectrogram from the same sample feed into the network, where the video features are fed into the Temporal Encoder and the mel-spectrogram is fed into the Acoustic and Background Encoders. Our disentanglement method is unsupervised because there is no explicit intermediate information representation as a training target. The outputs of the three encoders are jointly fed to the Mel Decoder to obtain the final reconstructed mel-spectrogram, and the generation losses are calculated with the real mel-spectrogram to guide the training of the generator.
In the training phase of the discriminator, for the Time-Domain Alignment Discriminator, the video features and mel-spectrogram from the same real sample are used as inputs to construct positive samples, while the real video features and the reconstructed mel-spectrogram are used as inputs to construct negative samples. For the Multi-Window Mel Discriminator, the real mel-spectrogram from the sample is used as a positive sample and the reconstructed mel-spectrogram is used as a negative sample input.
In the inference phase, we feed the video features into the temporal encoder, the mel-spectrogram of the reference audio containing the target timbre into the acoustic encoder, and the mel-spectrogram of the muted audio into the background encoder, and then generate the sound through the mel decoder. The choice of reference audio is arbitrary, depending on the desired target timbre. Theoretically, the length of the video features and reference audio input during the inference phase is arbitrary, but it is necessary to ensure that the relevant events are present in the video and that the reference audio contains the desired timbre to obtain the normally generated sound.
Model Structure and Configuration
Self-Gated Acoustic Unit

Each SGAU has two inputs and two outputs, which we call feature inputs, feature outputs, conditional inputs, and conditional outputs, respectively. The feature input receives the input vectors and passes through two layers of 1D convolutional layers, which we call the input gate, and then normalized by Instance Normalization. The conditional inputs receive the input vectors and then pass through two single 1D convolutional layers, which we call the output gate and skip gate. The output gate and the skip gate are both normalized by Group Normalization. The output of the jump gate is used as the output vector of the conditional output after the random resampling transform. Meanwhile, the output of the input gate is added with the output of the skip gate and the output gate, respectively, and then multiplied after different activation functions. The above result is transformed by Random Resampling and used as the output vector of the feature output.
For a clearer statement, the gated unit is described by the following equations:
$\mathbf{x_{o}}=\boldsymbol{R}[\tanh(\boldsymbol{W_{s}} * \mathbf{c_{i}}+\boldsymbol{V_{i}} * \mathbf{x_{i}}) \odot \sigma(\boldsymbol{W_{o}} * \mathbf{c_{i}}+\boldsymbol{V_{i}} * \mathbf{x_{i}})]$
$\mathbf{c_{o}}=\boldsymbol{R}[\boldsymbol{W_{s}} * \mathbf{c_{i}}]$
where $\mathbf{x_{i}}$ and $\mathbf{c_{i}}$ denote two inputs of the unit, $\mathbf{x_{o}}$ and $\mathbf{c_{o}}$ denote two outputs of the unit. $\odot$ denotes an element-wise multiplication operator, $\sigma(\cdot)$ is a sigmoid function. $\boldsymbol{R}[ \cdot ]$ denotes the random resampling transform, $\boldsymbol{W_{\cdot}}* $ and $\boldsymbol{V_{\cdot}}* $ denote the single layer convolution in skip or output gate and the 2-layer convolutions in input gate separately.
Model Configuration
We list hyperparameters and configurations of all models used in our experiments in Table:
| Module | Hyperparameter |
Size | Module | Hyperparameter |
Size |
|---|---|---|---|---|---|
| Temporal Encoder |
Input Dimension | 2048 | Self-Gated Acoustic Unit |
Input-Gate Conv1D-1 Kernel |
5 |
| Conv1D Layers | 8 | Input-Gate Conv1D-2 Kernel |
7 | ||
| Conv1D Kernel | 5 | Input-Gate Filter Size |
512 | ||
| Conv1D Filter Size | 512 | Output-Gate Conv1D Kernel |
3 | ||
| LSTM Layers | 2 | Output-Gate Conv1D Filter Size |
512 | ||
| LSTM Hidden Size | 256 | Skip-Gate Conv1D Kernel |
5 | ||
| Output Dimension | 8 | Skip-Gate Conv1D Filter Size |
512 | ||
| Acoustic Encoder |
SGAU Layers | 5 | Mel Decoder | ConvT1D Layers | 2 |
| LSTM Layers | 2 | ConvT1D Kernel | 4 | ||
| LSTM Hidden | 256 | ConvT1D Stride | 2 | ||
| Temporal Domain Aligment Discriminator |
ConvT1D Layers | 2 | ConvT1D Filter Size |
1024 | |
| ConvT1D Kernel | 4 | FFT Blocks | 4 | ||
| ConvT1D Stride | 2 | Background Encoder |
LSTM Layers | 2 | |
| ConvT1D Filter Size | 1024 | LSTM Hidden | 128 | ||
| Conv1D Layers | 4 | FFT Block | Hidden Size | 512 | |
| Conv1D Kernel | 4 | Attention Headers | 2 | ||
| Conv1D Filter Size | 512 | Conv1D Kernel | 9 | ||
| Training Loss | $\lambda_{m}$ | 1e5 | Conv1D Filter Size | 512 | |
| $\lambda_{a}$ | 1.0 |
Detailed Experimental Result
Baseline Model
Specifically, we build our cascade model using a video-to-sound generation model and a sound conversion model. The video-to-sound generation model is responsible for generating the corresponding audio for the muted video, while the sound conversion model is responsible for converting the timbre of the generated audio to the target timbre. We chose REGNET as the video-to-sound generation model, which has an excellent performance in the previous tasks. For the sound conversion model, we consider using the voice conversion model which is used to accomplish similar tasks, since there is no explicitly defined sound conversion task and model. We conducted some tests and found that some voice conversion models can perform simple sound conversion tasks. Eventually, we chose unsupervised SPEECHSPLIT as the sound conversion model because of the lack of detailed annotation of the timbres in each category in the dataset. The cascade model is trained on the same dataset (VAS) and in the same environment, and inference is performed using the same test data. In particular, instead of using speaker labels, our sound conversion model uses a sound embedding obtained from a learnable LSTM network as an alternative for providing target timbre information. The cascade model’s configuration follows the official implementation of the two models.
Evaluation Design
| MOS of Realism | |
|---|---|
| Score | Meaning |
| 5 | Completely real sound |
| 4 | Mostly real sound |
| 3 | Equally real and unreal sound |
| 2 | Mostly unreal sound |
| 1 | Completely unreal sound |
| MOS of Temporal Alignment | |
|---|---|
| Score | Meaning |
| 5 | Events in video and events in audio occur simultaneously |
| 4 | Slight misalignment between events in video and events in audio |
| 3 | Exist misalignment in some positions |
| 2 | Exist misalignment in most of the positions |
| 1 | Completely misalignment, no events in audio can match the video |
| MOS of Timbre Similarity | |
|---|---|
| Score | Meaning |
| 5 | Timbre is exactly the same as target |
| 4 | Timbre has high similarity with the target but not same |
| 3 | Timbre has similarity with the target, but there are obvious differences |
| 2 | Timbre has a large gap with the target, but share the same category of the sound |
| 1 | Timbre is completely different to the target |
We give the detailed definition of the MOS score on the subjective evaluation of audio realism, temporal alignment and timbre similarity in Table above, respectively.
In the evaluation of the realism of the generated audio, we will ask the raters to listen to several test audios and rate the realistic level of the audio content. The higher the score, the more realistic the generated audio.
In the evaluation of temporal alignment, we ask the raters to watch several test videos with their audio and rate the alignment of them. Samples with a shorter interval between the moment of the event in the video and the moment of the corresponding audio event will receive a higher score.
In the evaluation of timbre similarity, we ask the rater to listen to one original audio and several test audios and score how similar the test audio timbre is to the original audio timbre. For cosine similarity, we calculate the cosine similarity between the target audio and ground truth audio timbre features using the following equation:
$CosSim(X,Y) = \frac{ \sum \limits_{i=1}^{n}(x_{i} * y_{i})}{ \sqrt{ \sum \limits_{i=1}^{n}(x_{i})^{2}} \sqrt{ \sum \limits_{i=1}^{n}(y_{i})^{2} } } $
, and the timbre features are calculated by the third-party library. The higher the similarity between the test audio and the original audio sound, the higher the score will be.
Sample Selection
To perform the evaluation, we randomly obtain test samples for each category in the following way. Since our model accepts a video and a reference audio as a sample for input, we refer to it as a video-audio pair, and if the video and the audio are from the same raw video data, it will be called the original pair.
For audio realism evaluation, we will randomly select 10 data samples in the test set. After breaking their original video-audio pairing relationship by random swapping, the new pair will be fed into the model to generate 10 samples, and then mixed these generated samples with the 10 ground truth samples to form the test samples.
For the temporal alignment evaluation, we will use the same method as above to obtain the generated samples and use the ffmpeg tool to merge the audio samples with the corresponding video samples to produce the video samples with audio tracks. We also mix 10 generated samples and 10 ground truth samples to form the test video samples in the temporal alignment evaluation.
For the timbre similarity evaluation, we randomly select 5 data samples in the test set, and for each audio sample, we combine them two-by-two with 3 random video samples to form 3 video-audio pairs, 15 in total. The model takes these video-audio pairs as input and gets 3 generated samples for each reference audio, which will be used as test samples to compare with the reference audio.
For the ablation experiments, we only consider the reconstruction quality of the samples, so we randomly select 10 original pairs in the test set as input and obtain the generated samples.
MOS Results
| MOS Score | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Category | Audio Realism | Temporal Alignment | Timbre Similarity | ||||||
| Ground Truth | Baseline | Proposed | Ground Truth | Baseline | Proposed | Ground Truth | Baseline | Proposed | |
| Baby | $4.55 (\pm 0.10)$ | $2.67 (\pm 0.23)$ | $3.77 (\pm 0.15)$ | $4.43 (\pm 0.08)$ | $3.83 (\pm 0.17)$ | $4.07 (\pm 0.10)$ | - | $3.46 (\pm 0.17)$ | $3.94 (\pm 0.08)$ |
| Cough | $4.32 (\pm 0.11)$ | $3.30 (\pm 0.20)$ | $4.13(\pm 0.12)$ | $4.30(\pm 0.11)$ | $3.71(\pm 0.24)$ | $4.17(\pm 0.12)$ | - | $3.48 (\pm 0.22)$ | $3.59 (\pm 0.09)$ |
| Dog | $4.45 (\pm 0.11)$ | $3.21 (\pm 0.19)$ | $4.18 (\pm 0.11)$ | $4.45 (\pm 0.08)$ | $4.32 (\pm 0.15)$ | $4.40 (\pm 0.08)$ | - | $3.63 (\pm 0.15)$ | $4.09 (\pm 0.08)$ |
| Drum | $4.62 (\pm 0.08)$ | $2.91 (\pm 0.21)$ | $4.12 (\pm 0.15)$ | $4.56 (\pm 0.06)$ | $3.64 (\pm 0.16)$ | $4.25 (\pm 0.11)$ | - | $3.72 (\pm 0.13)$ | $3.85 (\pm 0.09)$ |
| Fireworks | $4.56 (\pm 0.09)$ | $3.16 (\pm 0.22)$ | $4.23 (\pm 0.13)$ | $4.47 (\pm 0.08)$ | $4.00 (\pm 0.21)$ | $4.35 (\pm 0.10)$ | - | $3.43 (\pm 0.25)$ | $3.93 (\pm 0.07)$ |
| Gun | $4.38 (\pm 0.12)$ | $2.76 (\pm 0.22)$ | $4.02 (\pm 0.15)$ | $4.45 (\pm 0.09)$ | $4.08 (\pm 0.17)$ | $4.25 (\pm 0.12)$ | - | $3.45 (\pm 0.18)$ | $3.98 (\pm 0.08)$ |
| Hammer | $4.43 (\pm 0.12)$ | $3.16 (\pm 0.26)$ | $3.84 (\pm 0.14)$ | $4.31 (\pm 0.08)$ | $3.88 (\pm 0.19)$ | $4.19 (\pm 0.13)$ | - | $3.74 (\pm 0.17)$ | $3.99 (\pm 0.10)$ |
| Sneeze | $4.04 (\pm 0.13)$ | $2.75 (\pm 0.22)$ | $4.00 (\pm 0.15)$ | $4.28 (\pm 0.12)$ | $3.76 (\pm 0.23)$ | $4.16 (\pm 0.11)$ | - | $3.62 (\pm 0.18)$ | $3.72 (\pm 0.08)$ |
| Average | $4.42 (\pm 0.04)$ | $2.99 (\pm 0.08)$ | $4.04 (\pm 0.05)$ | $4.41 (\pm 0.03)$ | $3.90 (\pm 0.07)$ | $4.23 (\pm 0.04)$ | - | $3.57 (\pm 0.07)$ | $3.89 (\pm 0.03)$ |
Cosine Similarity
| Category | Timbre Cosine Similarity | |
|---|---|---|
| Baseline | Proposed | |
| Baby | $0.86 (\pm 0.01)$ | $0.88 (\pm 0.00)$ |
| Cough | $0.86 (\pm 0.00)$ | $0.93 (\pm 0.01)$ |
| Dog | $0.77 (\pm 0.00)$ | $0.96 (\pm 0.00)$ |
| Drum | $0.74 (\pm 0.03)$ | $0.84 (\pm 0.00)$ |
| Fireworks | $0.88 (\pm 0.01)$ | $0.89 (\pm 0.01)$ |
| Gun | $0.83 (\pm 0.01)$ | $0.88 (\pm 0.01)$ |
| Hammer | $0.80 (\pm 0.02)$ | $0.89 (\pm 0.02)$ |
| Sneeze | $0.88 (\pm 0.01)$ | $0.98 (\pm 0.01)$ |
| Average | $0.84 (\pm 0.01)$ | $0.90 (\pm 0.01)$ |
Through the third-party evaluation on the Amazon Mechanical Turk (AMT), we obtained the evaluation results of our model.
As shown in the Table, the proposed model achieves scores closer to ground truth in terms of both audio realism and temporal alignment by comparing with the baseline model. The category of Dog and Fireworks have the best average performance in the two evaluations. The category of Baby gains the worst performance in the evaluation of audio realism and temporal alignment due to the uncertainty and diversity in human behavior which is hard for modeling, the same trend also appears in the category of Cough and Sneeze. Due to the imbalance in the amount of data in each category in the dataset, we can see that the four categories with smaller amounts of data (Cough, Gun, Hammer and Sneeze) will have overall lower temporal alignment scores than the four categories with larger amounts of data (Baby, Dog, Fireworks and Drum) in both evaluations, suggesting that the modeling of temporal alignment may be more sensitive to the amount of data.
In the evaluation of the audio quality, the baseline model achieved a relatively low score. This is because the cascade model accumulates the errors of both models during the generation process, bringing apparent defects to the generated audio, such as noise, electrotonality, or mechanicalness.
For the similarity of the timbre, the proposed model achieve higher scores both in the subjective and objective evaluation, which means the result of proposed model have a timbre closer to the ground truth than the baseline model.
We did not compare the generation speed because, empirically, the inference efficiency of a single model is usually much higher than that of a cascade model.
As a summary, by obtaining generation results and subjective evaluation results above, we have successfully demonstrated the effectiveness of our method and model.
Ablation Results
| MCD Scores | ||||||
|---|---|---|---|---|---|---|
| Category | Proposed | Generator Encoder Ablation | Discriminator Ablation | |||
| w/o Temporal | w/o Timbre | w/o Background | w/o Multi-Window Mel Discriminator |
w/o Temporal Domain Alignment Discriminator |
||
| Baby | $3.75(\pm 0.25)$ | $5.26(\pm 0.16)$ | $6.84(\pm 0.26)$ | $4.77(\pm 0.10)$ | $5.29(\pm 0.12)$ | $5.12(\pm 0.12)$ |
| Cough | $3.72(\pm 0.14)$ | $3.87(\pm 0.23)$ | $5.16(\pm 0.20)$ | $3.77(\pm 0.23)$ | $4.41(\pm 0.17)$ | $4.79(\pm 0.19)$ |
| Dog | $3.90(\pm 0.14)$ | $4.42(\pm 0.13)$ | $4.89(\pm 0.15)$ | $4.19(\pm 0.18)$ | $4.22(\pm 0.20)$ | $4.44(\pm 0.14)$ |
| Drum | $3.38(\pm 0.16)$ | $4.10(\pm 0.18)$ | $5.36(\pm 0.30)$ | $4.01(\pm 0.18)$ | $4.11(\pm 0.21)$ | $4.38(\pm 0.26)$ |
| Fireworks | $3.10(\pm 0.13)$ | $3.85(\pm 0.08)$ | $4.91(\pm 0.18)$ | $3.64(\pm 0.10)$ | $3.61(\pm 0.10)$ | $3.68(\pm 0.12)$ |
| Gun | $3.39(\pm 0.12)$ | $3.88(\pm 0.12)$ | $4.74(\pm 0.21)$ | $3.73(\pm 0.20)$ | $3.73(\pm 0.14)$ | $3.77(\pm 0.15)$ |
| Hammer | $3.47(\pm 0.16)$ | $4.95(\pm 0.14)$ | $4.53(\pm 0.17)$ | $4.05(\pm 0.27)$ | $4.02(\pm 0.17)$ | $4.39(\pm 0.13)$ |
| Sneeze | $4.04(\pm 0.18)$ | $4.50(\pm 0.15)$ | $5.91(\pm 0.38)$ | $4.34(\pm 0.13)$ | $4.58(\pm 0.22)$ | $4.97(\pm 0.20)$ |
| Average | $3.60(\pm 0.07)$ | $4.33(\pm 0.08)$ | $5.25(\pm 0.12)$ | $4.14(\pm 0.07)$ | $4.25(\pm 0.08)$ | $4.43(\pm 0.08)$ |
In the ablation experiment of the generator, we calculate the MCD scores for the generated result when one information component encoded by a certain encoder is removed as an objective evaluation. As shown in Table above, the generated results of our model achieve the lowest score on all experiments.
There is a phenomeon may evoke a confuse, since the audio with noise achieve a better score than the audio without it.
This is reasonable because there is a trade-off between audio reconstruction quality and audio quality due to the presence of background noise.
Specifically, the three parts of information are all necessary for the reconstruction of the target mel-spectrogram, and it will gain a larger distance between the generated result and the target audio when we discard one of the information, even if the information may conduct a negative impact on the quality of our generated results (e.g., the background noise).
Meanwhile, the above results can also corroborate the effectiveness of the background encoder in our model.
The results also show that timbre information has a more significant impact on the quality of the reconstructed audio than temporal information on average.
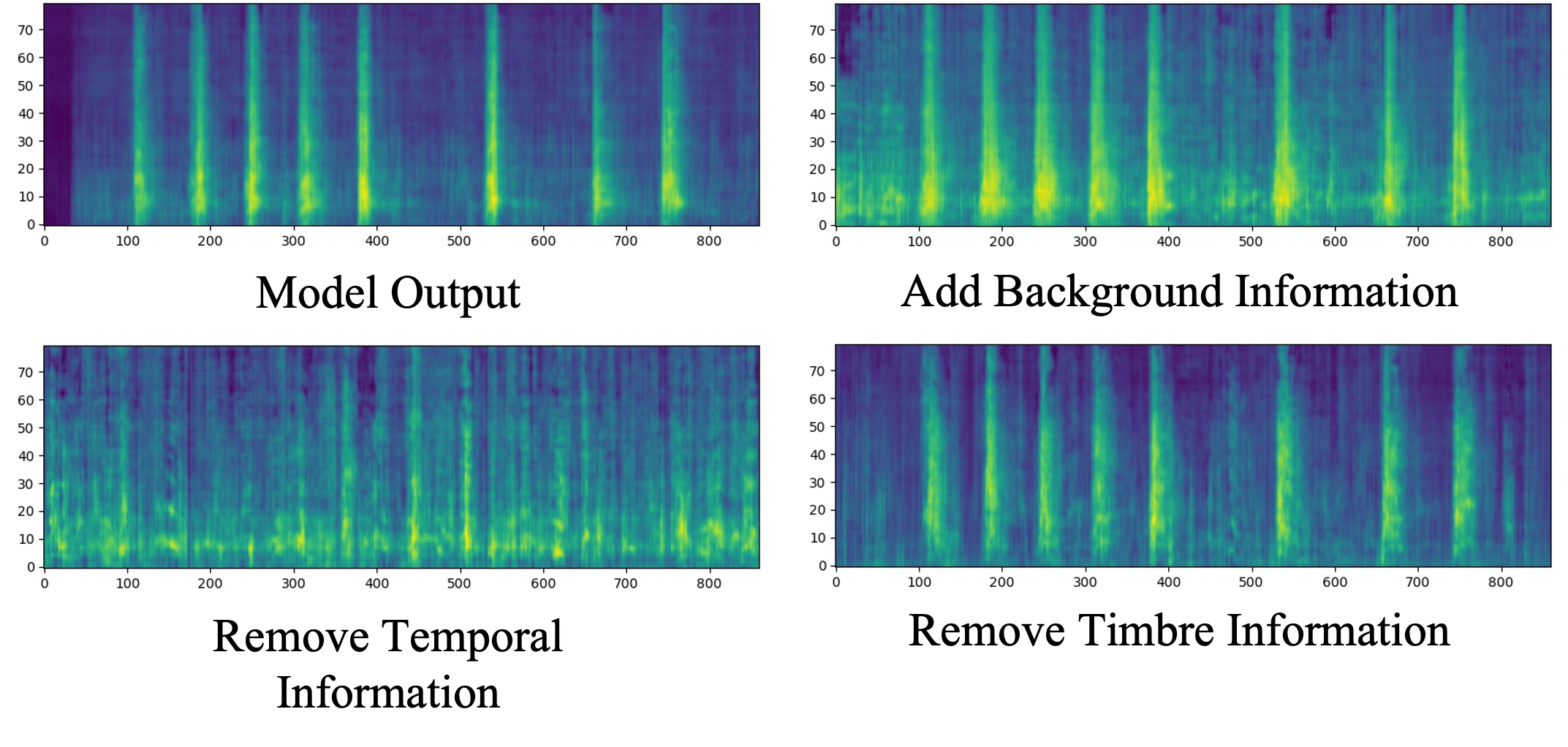 The generated result of our model acquires the minimum MCD score, which has successfully demonstrated the effectiveness of the encoders of our model.
To better illustrate the above experimental results, we compare the reconstructed mel-spectrogram when one information component is removed or added (by setting the input vector to Gaussian noise or zero), and visualize the mel-spectrogram reconstruction results as shown in Figure above.
As can be observed, when the temporal information is removed, the output mel-spectrogram becomes meaningless content that is uniformly distributed over the time series, and when the timbre information is removed, the output becomes a random timbre without specific spectral characteristics.
For the background information, when it is added during inference, the mel-spectrogram’s background noise becomes brighter.
The generated result of our model acquires the minimum MCD score, which has successfully demonstrated the effectiveness of the encoders of our model.
To better illustrate the above experimental results, we compare the reconstructed mel-spectrogram when one information component is removed or added (by setting the input vector to Gaussian noise or zero), and visualize the mel-spectrogram reconstruction results as shown in Figure above.
As can be observed, when the temporal information is removed, the output mel-spectrogram becomes meaningless content that is uniformly distributed over the time series, and when the timbre information is removed, the output becomes a random timbre without specific spectral characteristics.
For the background information, when it is added during inference, the mel-spectrogram’s background noise becomes brighter.
In the ablation experiments of discriminators, we retrain our model with one of the discriminators disabled. The experiments are performed under the same settings and configurations as before.
As can be observed in Table , the MCD scores of the generated results for almost all categories decreased to various extents after removing any of the discriminators.
On average, the impact of removing the Temporal Domain Alignment Discriminator is more significant than that of removing the Multi-window Mel Discriminator.
Due to the fact that the mel-spectrogram compresses the high-frequency components to some extent, some of the categories with high-frequency information content, such as Fireworks, Gun, and Hammer, do not have significant differences in the scores obtained after removing the mel discriminator.
Results Using Different Length Audio
(Take Dogs For Example)
| Sample Number | Ground Truth Audio From Video Sound Track | Reference Audio | Using 0.5x Length Reference Audio | Using 1.0x Length Reference Audio | Using 2.0x Length Reference Audio |
|---|---|---|---|---|---|
| Sample 1 | |||||
| Sample 2 | |||||
| Sample 3 |